

与其他的领域相比,社交和内容的监测与分析需求极为旺盛,供给却相当稀少。
但,社交数据和内容却能提供给我们独一无二的重要信息,企业也迫切想通过这些数据把握消费者的心态、情绪乃至欲求。
因为,人人都知道今天的互联网是每个人尽情抒发释放的渠道,内容以几何级数量增长,承载着浩如烟海的来自消费者的真实表达,并夹杂着各种因特定商业目的而发出的嘈杂声音,生机无限,又纷繁芜杂。
如同一个不断长大的蛮荒大矿脉,虽蕴含着金子,却一直缺乏能掘金采银的好工具。
不是没有工具,只不过这些工具不过是数据统计工具罢了,它们并不真正理解社交和内容背后的人的意思表示,可用于“计数”,但离真正的“分析”远矣。
唯有读懂“人语”方有真正的社交和内容分析,这在过去不过是“设想”与“概念”,今天则到了真正可能有突破性进化之时。
理解自然语言
“互联网分析在中国”在十多年前的一个“古董级”的刷屏文章《Sidney的IWOM监测与分析:理解和实践》中,提到了社交和舆情内容分析的最大挑战,是“汉语”。
让机器理解自然语言非常困难,因而,在当时我们采用了大量的人力,依靠“人脑和双手”解决问题。
但效率和准确性都不理想,管理成本却很高。所以这不是长久之计。
我以为这个情况很快就会改变,但令人失望的,这个不完美的方法,却在很多年以后依然不得不被使用。
不过这个情况悄然发生了改变。
近几年自然语言处理(NLP)的一些发展已经能相当程度上提升机器理解语言的效率,从而基本上能从“源头”解决内容和社交分析的最根本性问题。
一方面,得益于构建知识图谱,机器理解语境的状况比过去要更好。例如,“我喂给我的狗们一些馒头,但它们不爱吃。”以及“我喂给我的狗们一些馒头,因为它们快过期了。”机器应该如何理解这两个“它们”分别指的是谁呢?
如果没有知识图谱,机器完全无法分辨两种语境下“它们”究竟是馒头还是狗,现在则可以在知识图谱的帮助下进行分辨(狗才能吃,物品才会过期)。
除了知识图谱,另一个新的方法——预训练的语言模型也大大提升了NLP的效果。预训练的语言模型于2015年被提出,但直到近年才被证明在大量不同类型的任务中能起到非常有效的作用。语言模型嵌入可以作为目标模型中的特征,或者根据具体任务进行调整,从而能让机器在数据量十分有限的情况下有效学习。
能够正确解读自然语言,是social和内容数据监测与分析的一个重大突破,这意味着严肃的社交与内容分析成为现实。
构建知识图谱
前面已经提到了知识图谱,但它太重要,以至于必须单独拿出来。
过去的社交分析一直被诟病流于表面、缺乏深度。而深度的获得,必须要解决两个问题,第一,内容与内容之间的关联;第二,内容与知识的关联。
第一个问题举一个例子,过去的social listening能够挖掘到现象,却无法进行深度分析,典型如我们能够通过social listening了解到某一个婴儿奶粉品牌在大众心目中是“容易造成宝宝上火”的,但为什么会有这样的感觉呢?是某一个“谣传”所致,还是众多消费者在互不影响的情况下分别提出的“抱怨”?这需要机器对内容与内容之间的联系进行分析与解读,才能解决这个问题。——内容与内容之间的关联,只需要社交和内容分析工具能够全面的抓取数据,相对还是比较容易解决的。
第二个问题则必须知识图谱来解决。比如,有两个不同的消费者抱怨在宝宝食用了这个奶粉之后,有不适的表现,一个“眼睛分泌物增加”,另一个“便便干结”。这两个表现都被消费者认为是“上火”的症状,但在分析的时候,如果没有知识图谱,机器就不会把二者归类在同一个类别之下。内容与知识的关联是知识图谱最大的价值,其本质,是让机器能够像人一样“联想”。
某种程度上,自然语言处理只是让机器“认字”,而知识图谱才能帮助机器实现理解。真正的社交和内容分析,必须有知识图谱作为基础。
知识图谱的概念提出已经有很多年,目前知识图谱的三个核心信息抽取——属性抽取、实体抽取、关系抽取——算法都已经比较成熟,而且各行业已经积累了相当的语言语义的分类和结构化数据,进一步加强了知识图谱构建的效率和准确性。另外,知识图谱内的信息不是一成不变的,而需要随时间推移更新。知识图谱内的知识更新过去一直比较麻烦,现在技术上也有一定的突破,尤其是在目前知识融合和验证上,以及人工构建规则的经验积累也比过去要更好。可以认为,今天在汉语领域构建知识图谱的能力已经有相当的提高。
“互联网分析在中国”与AdMaster的高级研发总监Stanford关于这一领域有所沟通,Stanford向我们展示了AdMaster在该领域的大量投入与进步:AdMaster在多个场景的应用方面构建了知识图谱。自2015年起,AdMaster在整个行业最早着手推进了社交数据的标签化、规则化、AI化,以实现社交及洞察分析的实时化、自动化及智能化;同时专门组建了知识工程、深度学习、信息检索实验室。在数据清洗、知识抽取、知识融合均投入了大量的工作,所以应用能力也相当成熟,而在分行业构建知识库上,通过Scopa系统的全系档案和超级研判模块,也能够实现对行业知识库“与时俱进”的升级,即知识库的研究、推理及快速更新迭代。
不仅能“听”还要能“看”
另外一个我觉得非常有意思的,是social listening(社交监听)的说法看起来有些“过时”了。
因为,内容,尤其是社交内容,不仅仅只是文字,而是夹杂了大量的图片、视频以及音频。因此,突破social “listening”就非常重要,能够不仅听到,更能看懂听懂,才是真正意义上的social monitoring。
这同样必须基于人工智能,尤其是图像识别、语音识别和知识图谱技术。在这三者共同的协助下,内容与社交的分析正变得甚至比人工识别更加准确。
目前常用的方法,是利用图像识别,将图片或者视频中的各类元素识别出来,转化为带有权重的标签,并基于知识图谱识别其更准确的含义或者关联。
3年前,这一工作还很困难,识别准确性、速度都不够理想,今天则有突飞猛进的发展,并早已应用在社交和内容分析中。
智能之外的技术也在迅速革新
速度
第三个会有突破的社交与内容分析的领域是速度。
互联网用户在网上发出的各种声音浩如烟海,不可能全部人肉去看,必须机器抓取、机器处理。
目前,全网监测仍然非常困难,数据量太大,不现实,实时性也不佳。但并不是所有的工具都如此,例如,在特定平台内(例如微博、微信、各种论坛)利用AdMaster的Social BI的API实现的数据对接和处理速度已经可以实现“分钟级”,部分已经是“秒钟级”。
AdMaster的Stanford告诉“互联网分析在中国”,即使是利用爬虫,也能实现小时级。并且数据已经是机器精细处理之后的。
速度的突破至关重要,过去几年我的亲身体验,在处理IWOM(互联网舆情)数据时,基本上都是以“天”甚至“数天”为限才能输出机器初步处理的数据。现在则可以立等可见,是一个非常大的进步。
从“模糊科学”迈向BI
第四个特别重要的革新,是社交和内容的分析走向BI化。
社交与内容的监测与分析服务,过去几乎都得针对需求和项目的不同而专门开发加人力服务的方式实现,要么就只能如前面所述的,以数据统计为形式的很浅表的报告与结论。
专门开发的问题在于,不能开箱即用,实施周期与舆情出现的高实时性要求很不相符。
而且专门立项开发还很重,并且调整优化的灵活度还很差。但是社交和内容却是千变万化,常变常新的。
专门开发其实也不太容易保证质量,非标准化的解决方案,无从比较质量。
不仅如此,过去大部分的社交与内容的监测分析服务,都像模糊科学,你说它是科学吧,它给出的结论其实很相当定型化甚至比较模糊;你说它毫无价值吧,它又确实能够给出一点数据和见解。
但这一领域从来没有一个真正严谨且普适的数据产品,完全不像用户行为分析、DMP或是企业BI那么快速的发展并形成行业公认的标准。
这与社交和内容本身在这几年极为迅速的爆发形成鲜明的错位。
这样的情况肯定不会持续太久。
但社交与内容的监测与分析要走向成熟,必须从“模糊”的定制化,走向既要严谨的以BI的形态呈现,又可灵活定制的解决方案。
BI并非新鲜事物,但它强调的数据的既严谨又具可读性的展示、数据报告的可拓展和可下钻能力、可自配置的定制化分析能力、专用分析工具以及与业务场景相契合的模板都是传统社交与内容监测分析服务所缺乏的。
而可定制性,则决定了社交和内容分析工具的灵活性——即产品与功能可以高度定制,同时代码完全无需定制,部署速度和针对性可兼得。
如同手工的作坊必然被规范严格的大机器生产所替代,Social BI(社会化BI)或是Content BI(内容BI)也肯定会淘汰传统的舆情分析模式。
当然,企业客户对于系统定制化的需求依然是现实存在的,如何平衡好定制化需求和系统开发成本是解决问题的关键。例如,AdMaster解决这个问题的思路是将企业的定制化需求分为三个层级:表现层、逻辑层、数据层,在每个层次上既有标准化的通用方案可选,又有灵活的定制能力支持企业的不同需求。
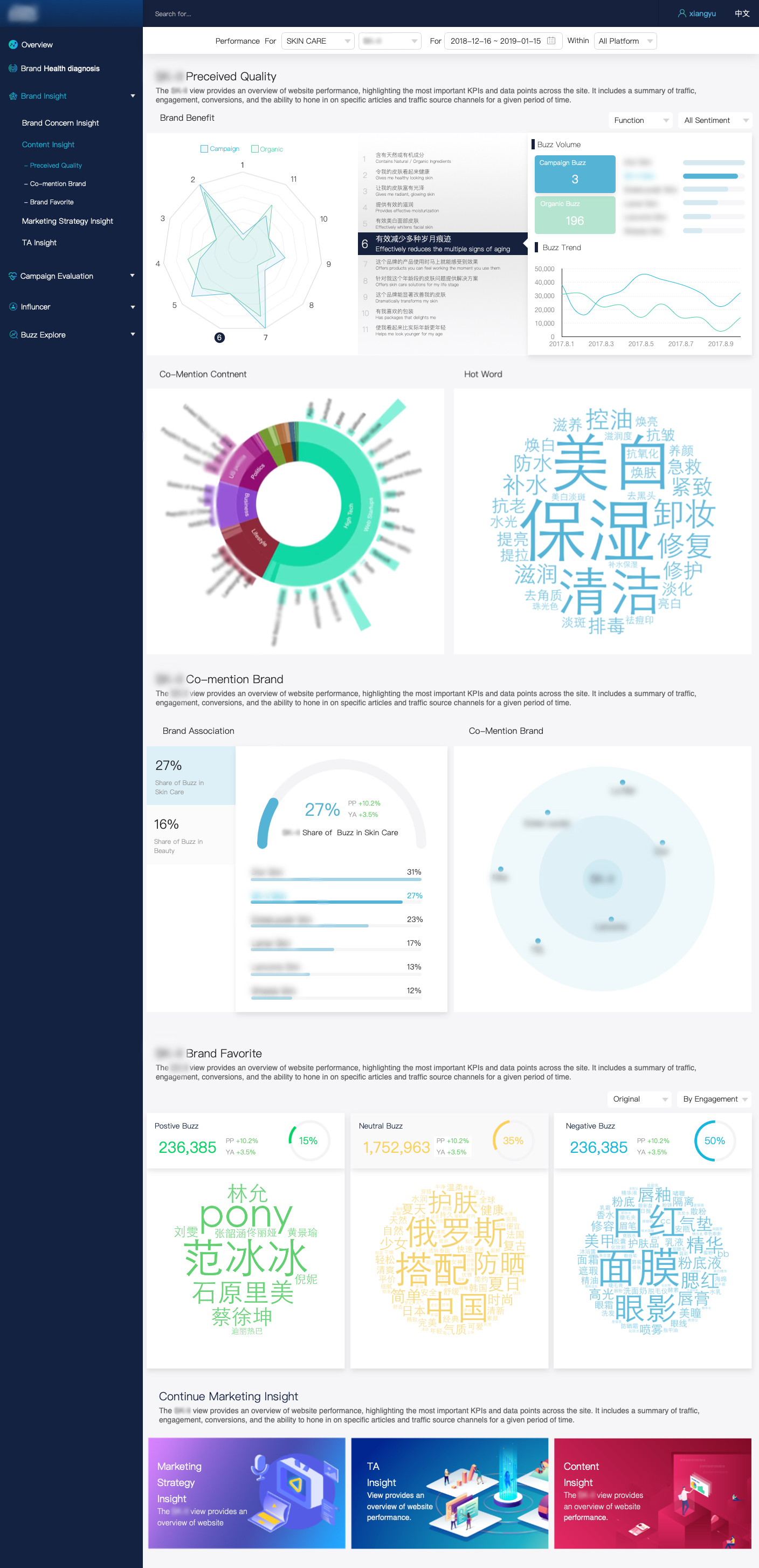
上图:AdMaster Social BI 系统界面,Social数据分析必须以严谨的BI的形式呈现,同时实现高度的定制化
技术革新之下,社交和内容数据分析的应用能有哪些突破呢?接着看。
突破与正被突破的应用
社交与内容分析的应用,业界的印象一直以来都是帮助企业在舆情中及时发现负面信息,或是总结文章发布之后到底能够传播多广多久。
这是传统的规则驱动和数据追踪模式下给出的惯常的解决方案,但显然不是今天人工智能加持下的social BI应该给出的解决方案。
新一代的Social BI必须为企业给出更为全面且更有深度的解决方案。
从“关键词触发”到理解消费者的“思想”
“互联网分析在中国”认为,这是social BI最值得突破也最能够有突破的领域。在NLP和知识图谱的帮助下,社交和内容分析对于消费者的“言辞”背后的“含义”,能够有更充分的理解与把握。
一个很有意思的案例,某汽车厂商,在推出一款新车之前,做了较大样本量的消费者调查,以衡量该车在消费者心目中的形象。调查的结果,“安全性高”是该车非常重要的消费者投票的特征。因此,厂商铺天盖地的广告均强调该车的安全性。但,该车在售卖之后,消费者在互联网上发出的声音则更多关注该车的“动力”问题,安全性则几乎无人讨论。
因此,营销的方向与策略,其实一开始就走偏了。但如果不做社交和内容分析,也许就真的这么一直将就错下去了。
这个故事的背后,需要知识图谱的帮忙,除了直接捕获“动力强大”这样的语言,消费者所讨论的“涡轮增压”、“推背感”、“轻松超车”等,其实都被归为“动力”话题之下。过去,这一工作需要人工阅读和分类来完成,今天的social BI已经能够很好的直接读懂消费者语言背后的含义。
这个案例并非孤立,企业所认为的品牌消费者感知,与消费者真正的感受常常存在非常显著的差异,这使企业对消费者真正在意的重点常常出现错误的理解或忽略。
例如,AdMaster的Social BI提供的一个例子,消费者对于汽车“智能化”的理解与企业自己的理解就有显著不同。企业方以为消费者对“智能化”的理解集中于“自动驾驶”,但对消费者真正的内容与社交分析之后,我们可以看到,“辅助驾驶”而非“自动驾驶”,才是消费者心目中对“智能化”所真正在意的。

上图:AdMaster的Social BI对于消费者关于“智能化”认知上与企业的显著差异
没有什么比直接询问所有消费者内心所想更能帮助企业找准自己的市场与品牌的定位,显然,social BI很应该在这一领域给出答案,并且没有其他的方法比它更好。
发现“微观KOL”
第二个很值得social BI去解决的问题是发现“微观KOL”。
我们当然知道哪些名人(比如明星或是大学问家)是自带流量的KOL,但他们太贵了,而且,他们的影响力实际上也太宽泛了。
“微观KOL”不同,他们是KOL中的“小微企业”,靠专业和特色取胜,有自己稳定的、深入交流的粉丝群,尽管粉丝数量并不巨大,但粉丝圈子内的号召力惊人。
找到“微观KOL”无法靠人工,必须依赖于利用人工智能的社交关系图谱,以及内容分析,找到那些真正的“话题终结者”与意见领袖。
这一功能,今天已经能够产品化的提供给企业寻找影响力中心人群所用了。例如,下图所示的由AdMaster抓取的基于微博中用户的连接情况,实际上包含了两个数据关系:第一,所有的用户都是对“香水”这一主题感兴趣的用户;第二,用户间相互关联关系提供了谁在这个主题内更具有影响力。图中图标较大的,即是这个“香水”社群中更核心的KOL。
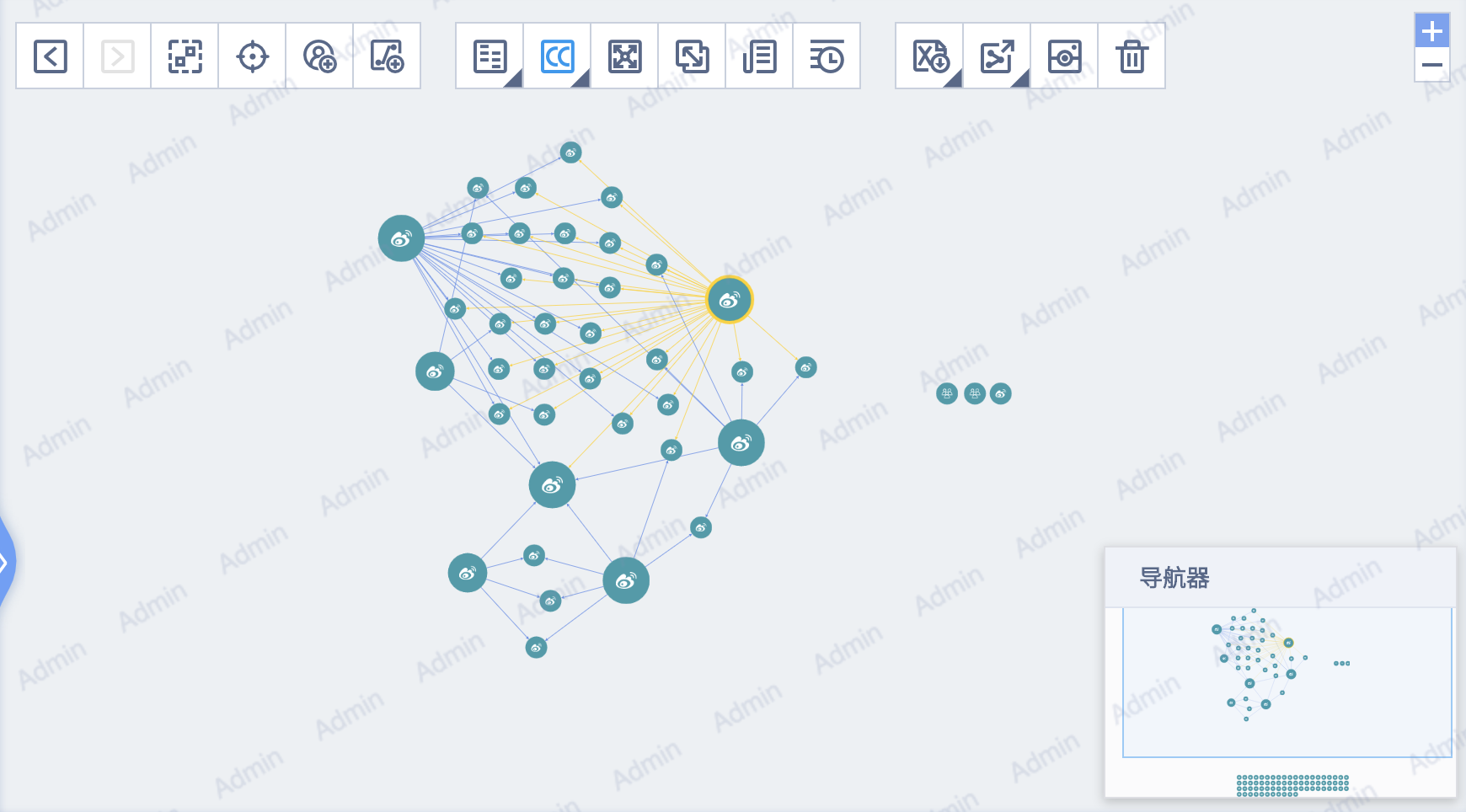
比如,下图中的KOL,它的粉丝虽然只有数万,但在香水粉丝中非常有地位与影响力。
发现“水军”
与发现“微观KOL”一样,人工智能同样能够帮助我们快速发现水军。
简单讲,那些具有固定模式的账号(异常的社交关系、异常的行为等)、呈现某种固定模式的内容等,通过建立人工规则和机器学习实际上能够被快速鉴别。
这并非特别困难的需求,新的social BI肯定必须有这样的功能。
真实粉丝数与真实阅读量
Social BI应该在挖掘真实粉丝数与真实阅读量上给予强大的支持。与发现“水军”一样,通过机器学习,对僵尸账号的识别也是social BI的分内工作。
另一方面,真实阅读量,尤其是微信文章的真实阅读量,在今天一直缺乏较好的解决方案,但social BI作为能够对社交帐户和内容号做分钟级监测的系统,或可以通过阅读量的异常增长发现作弊。
不过,更准确的扫除虚假阅读量的需求似乎仍然对social BI存在挑战,这也是我最期待能有重大突破的领域。
总结
社交与内容的数据监测与分析持续在“1.0时代”的时间之久,令人咋舌。但这一情况在今年肯定会有重大的改观。机器学习与人工智能技术已经深度融合在这一领域形成可供落地的数社交与内容数据应用能力,而将这些能力产品化,深度整合AI+BI的新一代社交和内容数据平台是必然选择。
我们相信,更好的更接近于人的智慧与理解的社会化分析,以及,被称为social BI的更严谨的社交和内容的分析,才是社交与内容数据分析与应用发展的未来主流。当机器能够像人一样读懂人的意思,却又比人的速度快千万上亿倍,没有任何理由这个领域不迸发出难以想象的创新玩法与巨大潜能。